
Self-playing Adversarial Language Game Enhances LLM Reasoning
📄 Cheng et al. (2025) Self-playing Adversarial Language Game Enhances LLM Reasoning
(arXiv:2404.10642v3 [cs.CL])
Part 3 of a series on the SPAG paper.
In this section, we cover:
- Adapting LLMs to game rules via imitation learning
- Transitioning from GPT-4 demonstrations to self-play
- Offline RL approaches and reward shaping
- Balancing specialized training with broader language abilities
3. Learning Strategies & Training
Having established the adversarial game in Section 2, the paper now describes how the LLM is trained to act as both Attacker and Defender, and how it ultimately refines its reasoning capabilities. The overall process occurs in two main stages:
- Imitation Learning – where the LLM learns from GPT-4’s demonstrations of the game, ensuring it follows the rules and develops basic proficiency in both roles.
- Self-Play Reinforcement Learning – where the model competes against itself (a copy of its own policy), generating game episodes offline and updating its parameters to maximize (or minimize) the adversarial reward.
Beyond these broad stages, the authors detail policy optimization methods, offline RL considerations, and additional stability techniques that prevent the model from catastrophically forgetting general language capabilities. This section provides a comprehensive explanation of each component.
3.1 Imitation Learning with GPT-4
Motivations for an Initial Imitation Phase
While LLMs are highly capable language generators, they do not a priori know the specific rules of Adversarial Taboo nor how to conform to them. If the model is simply thrown into self-play from scratch, it might violate the game instructions (e.g., the Attacker might explicitly reveal the target word, or the Defender might guess without any evidence). Therefore, the paper introduces an imitation learning (IL) phase:
- Game Awareness: Ensure the model comprehends the concepts of “attacker,” “defender,” “target word,” and “prohibited utterances.”
- Basic Strategy & Etiquette: Demonstrate typical turn-taking, rule-following behavior, and fundamental examples of cunning hints or safe guesses.
- Leverage GPT-4 Quality: GPT-4 has robust reasoning and rule-following abilities. Recording GPT-4’s self-play dialogues yields high-quality trajectories for IL.
Data Collection & Setup
The authors enlist GPT-4 to play the Taboo game against itself, using system prompts that specify who is the Attacker and who is the Defender. For each target word , GPT-4 generates a full multi-turn episode. This yields a dataset of (state, action) pairs:
- Attacker Episodes: If GPT-4’s Attacker eventually wins, that game’s action sequences are assigned to an “attacker-winning” subset, .
- Defender Episodes: Conversely, if the GPT-4 Defender wins, the sequences go into .
- Ties or Invalid Rounds: Typically discarded or handled separately, as they provide less straightforward examples of “winning moves.”
Because GPT-4 is a powerful model, the authors trust that these demonstrations illustrate reasonable strategies without systematically exploiting obvious shortcuts or ignoring instructions.
Imitation Loss
For the LLM parameterized by , the IL objective is to match the probability distribution of winning demonstrations from GPT-4. Let be the base pretrained model (e.g., LLaMA-2, Baichuan-2) before any fine-tuning. Then, for the attacker-winning trajectories, the paper defines:


where is the attacker’s chosen utterance at turn , is the prior state, and is the prompt template that instructs the model to respond as Attacker. The first term enforces maximum likelihood matching of GPT-4’s moves, while the second term is a KL regularizer with coefficient , discouraging the model from drifting too far from its pretrained linguistic knowledge.
Similarly, for defender-winning trajectories:
The total IL loss is typically an average:
In practice, the model is trained on attacker-winning and defender-winning episodes separately, ensuring it sees both perspectives and inherits GPT-4’s well-structured gameplay.
Outcome of Imitation Learning
By the end of this phase, the LLM can:
- Act in compliance with the Taboo rules (e.g., an Attacker that never blurts out the target word, a Defender that guesses exactly once).
- Demonstrate baseline success in the game, albeit limited by the demonstration data.
It is not yet fully optimized—GPT-4’s moves are strong but not necessarily exhaustive of all strategies. This is why the paper proceeds to a self-play regime next.
3.2 Transitioning to Self-Play
Motivation for Self-Play
Post-imitation, the model has learned “good enough” gameplay but might still exhibit suboptimal or predictable moves. Human data or GPT-4 data alone can be expensive to scale. Self-play offers a powerful alternative: the model generates new episodes on its own, effectively creating an unlimited supply of training data as it iteratively improves.
Moreover, the adversarial nature of Taboo means any deficiency in the Attacker’s cunning or the Defender’s inference will be exploited by the other role. This mutual feedback loop is what drives more sophisticated behavior—analogous to how, in board games, a strategy that once sufficed is later recognized and countered by an improving opponent.
Practical Mechanism
The paper details how a copy of the model, , is made at each iteration. One copy is assigned the Attacker role, another copy the Defender role. A large set of target words is sampled. For each , the Attacker–Defender pair engages in a multi-turn game until it reaches a conclusion: attacker win, defender win, or tie.
This generates a dataset of self-play trajectories, denoted . The next step is to apply reinforcement learning updates to using . Crucially, the entire process can iterate multiple times, producing increasingly difficult or clever dialogues.
3.3 Reinforcement Learning from Self-Play
Zero-Sum Objective
Recall from Section 2.3 that we have a zero-sum reward structure:
- If the Attacker succeeds in tricking the Defender, .
- If the Defender correctly identifies the target word, .
- Ties typically yield .
For a trajectory , let denote the Attacker policy and the Defender policy, both instantiated by the same LLM with different prompts. The training goal is to maximize the Attacker’s expected return if we are focusing on , and minimize that same return if we are focusing on . Symbolically,
When using a single model for both policies, the authors effectively do separate RL updates for the Attacker component and the Defender component on their respective winning trajectories.
Offline RL and the Importance of Stability
A naive approach might attempt online RL, sampling a trajectory, updating the model, then sampling more episodes from the updated policy. However, online RL is computationally expensive for LLMs, since each iteration requires tens of thousands of dialogues. Hence, offline RL is used: a batch of self-play episodes is collected once from ; then is improved offline on that fixed batch.
Key Stability Concern: LLMs are prone to catastrophic forgetting or degenerate optimization if large policy updates are made from static data. The authors incorporate:
- KL Regularization w.r.t. to constrain the updated policy from straying too far in a single step.
- SFT Data Mixing to preserve general language capabilities, blending in supervised instruction data with the RL objectives.
3.4 Policy Optimization and Loss Functions
Advantage-Based Offline Updates
Let be the self-play dataset collected from the “frozen” policy . For each trajectory , define an advantage function that measures the relative value of action in state compared to a baseline. In practice, the authors approximate:
where is a discount factor, is the immediate reward, and is the value function. They then use importance sampling to update :
ReST (Reinforced Self-Training) Approach
A notable simplification is the adoption of a threshold-based approach akin to ReST, where only the winning episodes for each role are used for that role’s policy update. Specifically:
- For the Attacker, filter episodes where .
- For the Defender, filter episodes where .
Such “self-imitation” techniques (also explored in prior RL literature) help the policy reinforce only successful trajectories, stabilizing training. Episodes with negative returns for a given role effectively do not feed into the gradient for that role.
KL Regularization & Multi-Objective Loss
To prevent the updated policy from diverging from or forgetting crucial language skills, the final self-play training objective is typically expressed as:
Here:
- is a KL coefficient controlling the update magnitude.
- scales the supervised fine-tuning (SFT) term to maintain general linguistic competence.
The authors note that this mixture of RL on winning episodes plus supervised data offers the best of both worlds: it capitalizes on emergent strategies from self-play while anchoring the model to broader language skills.
3.5 Offline RL and Episode Collection
Sampling Process (Algorithmic View)
The paper provides Algorithm 1 (for data collection) and Algorithm 2 (for iterative self-play epochs). In essence:
- Copy Model: Create as a snapshot of the current policy.
- Generate Episodes:
- For each , have self-play one Taboo match as Attacker vs. Defender.
- Log all states, actions, and final outcomes (win/loss/tie).
3. Filter & Update: Split episodes into attacker-winning and defender-winning . Apply the RL objective in an offline manner.
4. Repeat: Once training converges or a set number of epochs is reached, move on to final evaluation.
Convergence & Practical Considerations
- Epochs of Self-Play: The paper typically runs multiple epochs (e.g., 1 to 3) of self-play. Each epoch yields a new policy that is more skilled than the previous.
- Computational Cost: Although massive, the offline nature reduces the overhead compared to naive online RL, since one large batch of dialogues can be generated, then used for multiple gradient passes.
- Incentive to Communicate Less: Because each side can lose by “revealing too much,” the authors observe that over time the conversations tend to become more succinct or strategic, a phenomenon evidenced in the reported game-play dynamics.
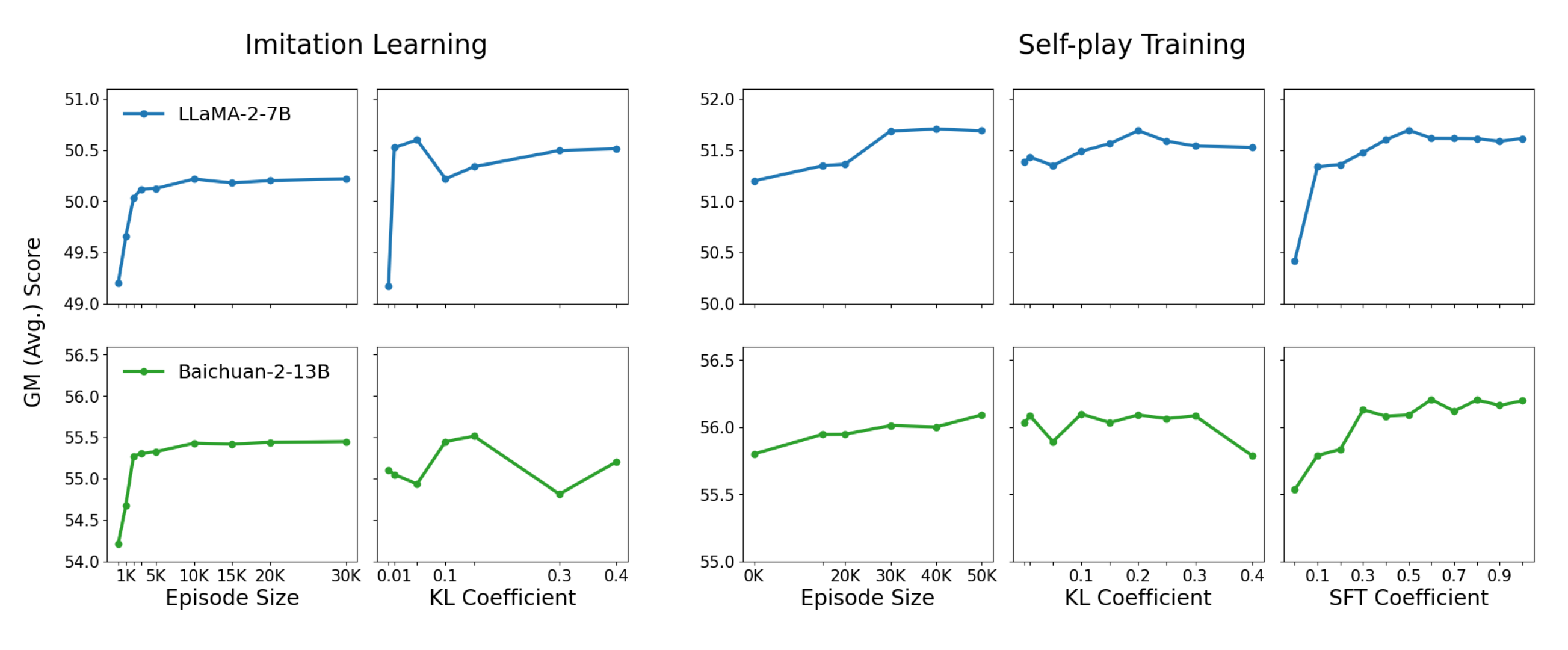
Figure 3, showing ablation studies on hyperparameters such as episode size, KL coefficients, and SFT mixing ratios, indicating sample efficiency and performance trends in reasoning tasks. This figure validates the effectiveness of the offline RL approach.
Summary of Section 3
- Imitation Learning: GPT-4 data is used to warm-start the LLM, ensuring adherence to game rules and basic strategic proficiency.
- Transition to Self-Play: The model then generates its own adversarial dialogues, greatly expanding the variety of training examples.
- Reinforcement Learning: A zero-sum reward structure, offline dataset of self-play episodes, and advantage-based policy updates converge to more refined gameplay.
- Stability Mechanisms: KL regularization and a persistent SFT term safeguard against overfitting on the game at the expense of overall language quality.
Section 4 will turn to experimental results, showing how these learning strategies boost both in-game performance (win rates, compliance with Taboo rules) and general reasoning as measured on external NLP benchmarks.