
Self-playing Adversarial Language Game Enhances LLM Reasoning
📄 Cheng et al. (2025) Self-playing Adversarial Language Game Enhances LLM Reasoning
(arXiv:2404.10642v3 [cs.CL])
Part 4 of a series on the SPAG paper.
In this section, we cover:
- Setup and metrics for evaluating LLM reasoning
- Win rates and gameplay outcomes against various baselines
- Gains on reasoning benchmarks beyond the game
- Emergent trends in dialogue length and strategy
This section presents the empirical results of training large language models (LLMs) through Self-Play of Adversarial Taboo (SPAG). The paper’s goal is twofold: (1) to demonstrate that self-play in a language game can enhance an LLM’s in-game performance—reflected by higher win rates and better adherence to rules—and (2) to show that the same training regime yields broader improvements in reasoning tasks outside the game. The authors evaluate on a suite of standard NLP benchmarks and compare their method against both supervised fine-tuning (SFT) baselines and alternative multi-agent approaches.
4.1 Experimental Setup
Model Backbones
The experiments use two open-source models:
1. LLaMA-2-7B
2. Baichuan-2-13B
These serve as the base pretrained checkpoints () before any Taboo-related training. Both models have demonstrated solid capabilities in general language tasks but are not inherently specialized for multi-turn adversarial reasoning.
Data Sources
-
Imitation Data (GPT-4 Episodes):
The authors collect a substantial set of game episodes where GPT-4 plays both Attacker and Defender. Each target word in a subset of the vocabulary prompts a new self-play round, ensuring coverage of diverse semantic fields. These dialogues provide high-quality demonstrations for the initial Imitation Learning phase. -
Self-Play Episodes:
After the LLM has completed imitation learning, it plays Taboo against itself to generate new trajectories. The full target vocabulary can reach 50,000 words (excluding stop words). In each iteration (or epoch) of self-play, thousands of dialogues are gathered for reinforcement learning (RL) updates. -
Supervised Fine-Tuning (SFT) Data:
To avoid catastrophic forgetting of general language skills, the authors periodically blend in standard instruction-following data (e.g., Alpaca). This ensures the model remains well-rounded, rather than overfitting solely to the adversarial game.
Training Stages
- Imitation Learning (IL):
- Objective: Familiarize the model with Taboo’s rules by maximizing the likelihood of GPT-4’s winning moves.
- Output: An “Imitation Model” that follows the game structure and can achieve basic success.
- SPAG Self-Play (Offline RL):
- Process: A copy of the model generates new dialogues by playing Attacker vs. Defender.
- Filtering: Winning trajectories are used to reinforce the winning side, while losing trajectories go to the opponent’s gradient updates.
- Repeating Epochs: Each iteration refines the policy, leading to incremental improvements in both the game and reasoning tasks.
Evaluation Metrics
- Reasoning Benchmarks:
- MMLU (Massive Multitask Language Understanding)
- BBH (BIG-Bench Hard)
- ARC-e / ARC-c (AI2 Reasoning Challenge, Easy/Challenge)
- Mutual, WinoGrande, LogiQA2, PIQA
These collectively assess the model’s logical coherence, commonsense inference, multiple-choice accuracy, and subject-specific knowledge.
- Game Win Rates:
- Against GPT-4: Each tested model either plays as Attacker or Defender, while GPT-4 serves as the opponent.
- Against Different Epoch Checkpoints: Models at successive training epochs face each other, revealing how the Attacker and Defender roles improve over time.
- Dialogue Statistics:
- Average Turns per game
- Utterance Length to gauge whether strategies evolve toward more efficient or obfuscated forms of communication.
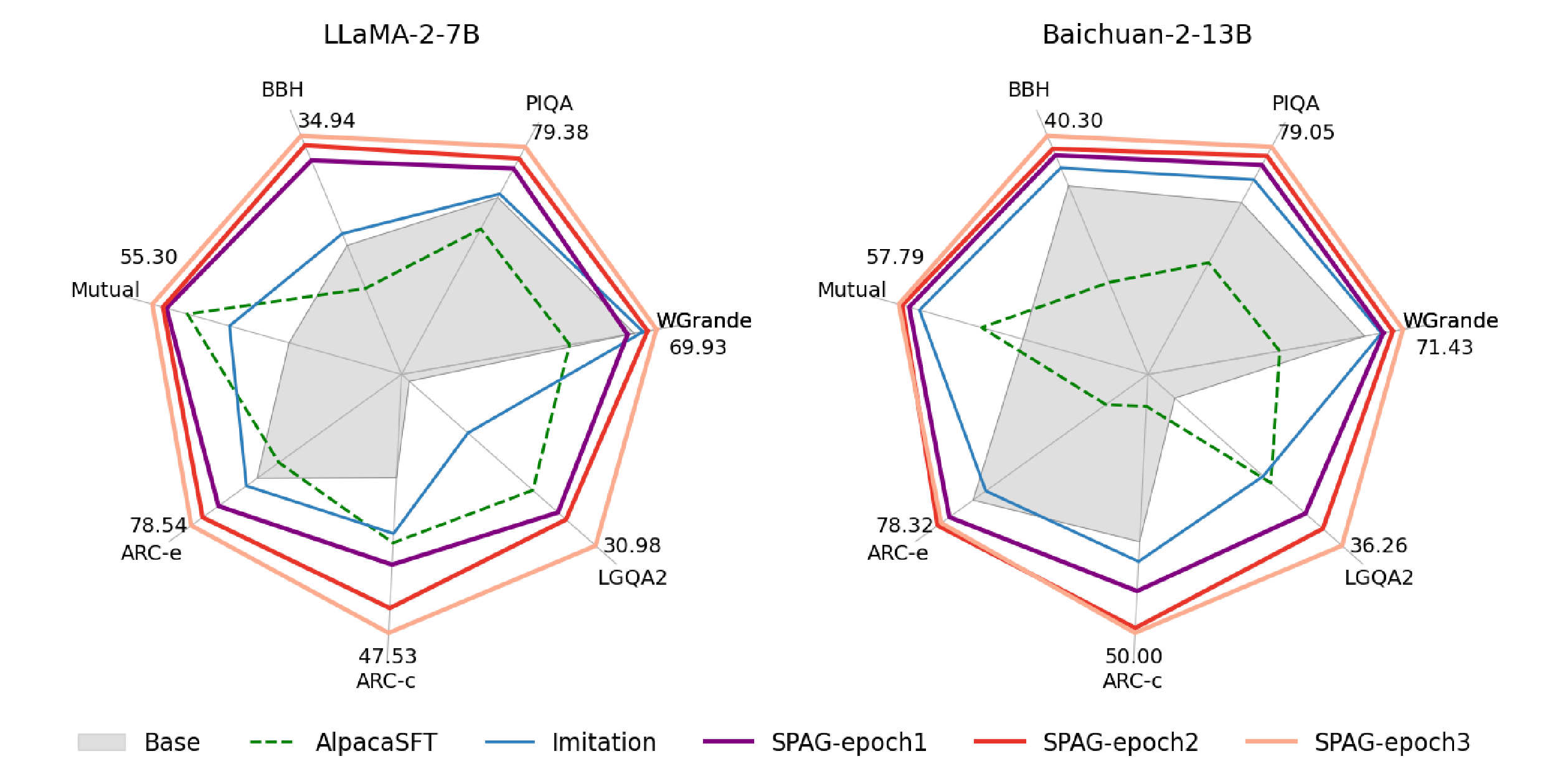
Figure 1, displaying a radial (or polygonal) chart of reasoning improvements across multiple benchmarks (e.g., MMLU, ARC, BBH). Each axis is normalized to highlight the continuous gains with self-play epochs.
4.2 Evaluation on Reasoning Benchmarks
One of the paper’s most striking claims is that training on Adversarial Taboo benefits general LLM reasoning, not merely in-game skill. To test this, the authors evaluate each checkpoint on standard benchmarks:
-
Initial (Base) Performance:
LLaMA-2 and Baichuan-2, before any Taboo-related fine-tuning, achieve baseline scores on tasks like MMLU, BBH, ARC, etc. These results serve as reference points to quantify how much Taboo training shifts the model’s zero/few-shot performance. -
Imitation-Learned (IL) Models:
After ingesting GPT-4’s gameplay, both LLaMA-2 and Baichuan-2 show uniform improvements in reasoning accuracy. This occurs because the IL data itself covers a range of semantic fields and enforces strategic communication, effectively teaching certain patterns of multi-turn reasoning. -
Self-Play Reinforcement (SPAG):
- SPAG-1, SPAG-2, SPAG-3: The models are progressively trained through multiple self-play epochs.
- Each epoch yields additional gains, especially on logical or commonsense tasks (e.g., WinoGrande, LogiQA2).
- A portion of the benchmarks (e.g., MMLU) might see minor fluctuations, but overall, the geometric mean of performance rises steadily.
- Comparison to Other Methods:
- Chain-of-Thought (CoT) prompting typically improves performance on a subset of tasks but depends heavily on prompt quality.
- Continuous Supervised Fine-Tuning (SFT) can improve or degrade performance depending on the data composition. Often, models overfit to instruction tasks at the expense of general reasoning.
- Non-Adversarial Self-Play (like 20-Question or Guess-My-City) yields smaller gains in test benchmarks, presumably because these tasks do not pit two roles in direct opposition. Without the strategic push-and-pull of an adversarial environment, emergent complexity is limited.
Quantitatively, the paper reports 2–4% absolute improvements on tasks like ARC Challenge and BBH from IL to SPAG. While the percentage might seem modest, these tasks are notoriously difficult, and incremental gains often indicate significantly improved reasoning patterns.
4.3 Performance Improvements & Trends
Uniform Gains vs. Specific Tasks
A key observation is that the SPAG approach tends to boost performance across a broad spectrum of benchmarks. Tasks that emphasize logical consistency, inference, and multi-step reasoning see the most benefit. On the other hand, tasks demanding pure factual knowledge (like certain MMLU subsets) may not see as large a jump, since those rely more on memorized facts than on strategic or adversarial thinking.
Continuous Improvement Over Epochs
The authors conduct three self-play epochs:
- SPAG-1: Gains from 0 or partial game expertise to a consistent improvement across tasks.
- SPAG-2: More robust on tasks requiring reasoning depth; the Attacker–Defender strategies become sharper.
- SPAG-3: Additional but smaller improvements, suggesting diminishing returns, though overall performance is still on an upward trend.
Figure 1 (revisited)
In the paper, the radial chart shows how, by SPAG-3, the LLM approaches or surpasses best-known baselines on tasks like ARC Challenge and WinoGrande.
4.4 Comparisons with Baselines
To demonstrate that adversarial self-play is crucial, the authors consider multiple baselines:
- Alpaca SFT Only
- Fine-tuning the base model on a well-known instruction dataset (Alpaca).
- Results: Some improvements in general question-answering, but less or no improvement on specialized reasoning tasks.
- Chain-of-Thought (CoT)
- Prompting the base model to show intermediate steps.
- Results: Improves tasks like BBH in some contexts, but not as consistently across the entire suite of benchmarks.
- Non-Adversarial Games
- 20-Question and Guess-My-City are used for imitation or self-play. While these tasks also revolve around a target word, they do not feature conflicting objectives.
- Results: Gains are smaller and do not appear to generalize as effectively.
Overall, SPAG emerges as uniquely powerful due to the zero-sum tension and the requirement for each role to out-reason the other. By forcing strategic trade-offs (e.g., “Can I hint at this concept without giving the entire secret away?”), it triggers deeper cognitive patterns than simpler or cooperative tasks.
4.5 Ablation Studies & Hyperparameter Analysis
Data Size & Sample Efficiency
The authors vary:
- Imitation Dataset Size: Ranging from a few thousand GPT-4 episodes to tens of thousands.
- Self-Play Episode Count: Considering 5k, 10k, or more dialogues per epoch.
They find that the largest gains from imitation arrive at roughly 5k–10k demonstrations, after which performance saturates. Conversely, repeated self-play continues to provide diminishing but notable increments, illustrating that each new batch of adversarial dialogues can reveal fresh strategies.
KL Coefficients & Reward Thresholds
As mentioned in Section 3, the combination of:
- A moderate KL penalty (e.g., 0.1–0.2)
- A reward threshold that selects only winning episodes for each role’s update
leads to more stable training. Aggressive KL constraints can stifle improvement, while too lenient constraints risk overfitting the language model to Taboo strategies, undermining broader language performance.
Mixing SFT Data
A balancing term ensures that each RL update also includes some supervised fine-tuning data. The paper shows that setting is effective in preserving overall fluency and preventing the model from becoming too “Taboo-centric.”
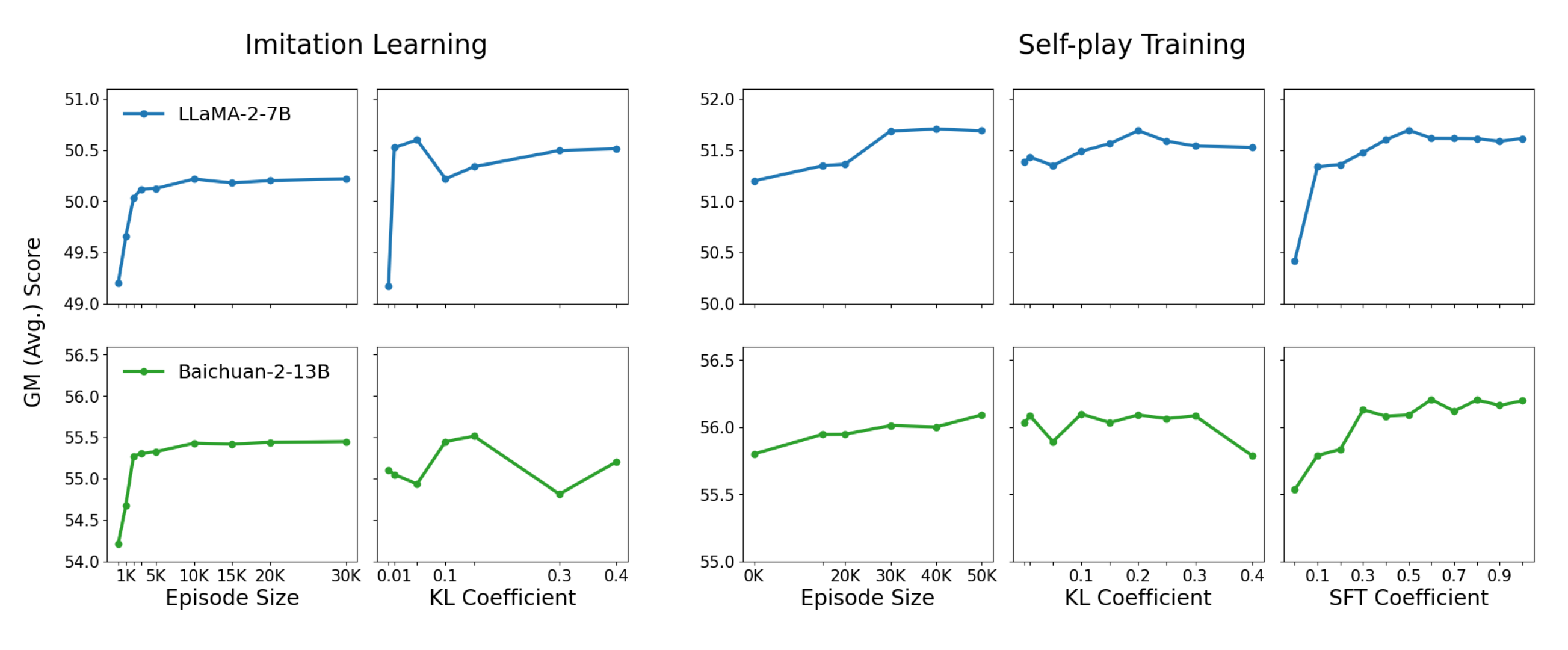
Figure 3: Ablation overview, displaying plots of geometric mean scores vs. KL coefficient, vs. dataset size, and so forth.
4.6 Game-Play Dynamics
Win Rates Against GPT-4
One direct measure of success is how often the trained Attacker can fool GPT-4, or how often the trained Defender can resist GPT-4’s Attacker. The authors run the trained model as Attacker/Defender across a curated test set of target words (e.g., 168 objects or typical nouns). Over successive self-play epochs, both roles become increasingly effective, evidenced by:
- Attacker’s Win Rate: Surges initially when the model learns cunning ways to coax the Defender into saying the forbidden word.
- Defender’s Win Rate: Catches up as soon as it recognizes the Attacker’s hints and responds carefully.
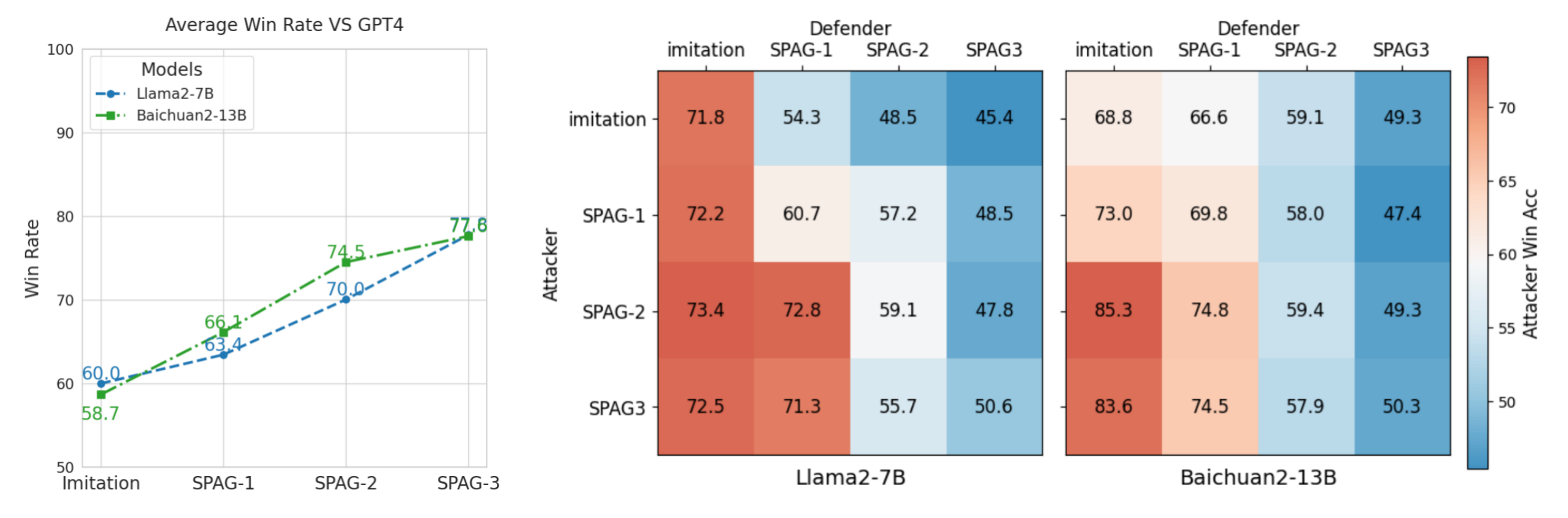
Figure 4: Depicts the model’s win rate (Attacker or Defender) against GPT-4 across successive epochs. The Attacker line typically starts lower (before imitation learning) then rises significantly, while the Defender line improves in tandem.
Dialogue Length & Interaction Patterns
The paper notes a fascinating emergent behavior: with repeated adversarial training, dialogues become succinct. Both Attacker and Defender learn that prolonging conversation can be risky—the more they speak, the higher the chance of accidentally losing. Over the course of training:
- Turn Count Drops: The Attacker may push for decisive statements quickly, and the Defender either guesses earlier or remains guarded.
- Utterance Length Shortens: Agents converge on more direct or cryptic phrasing.
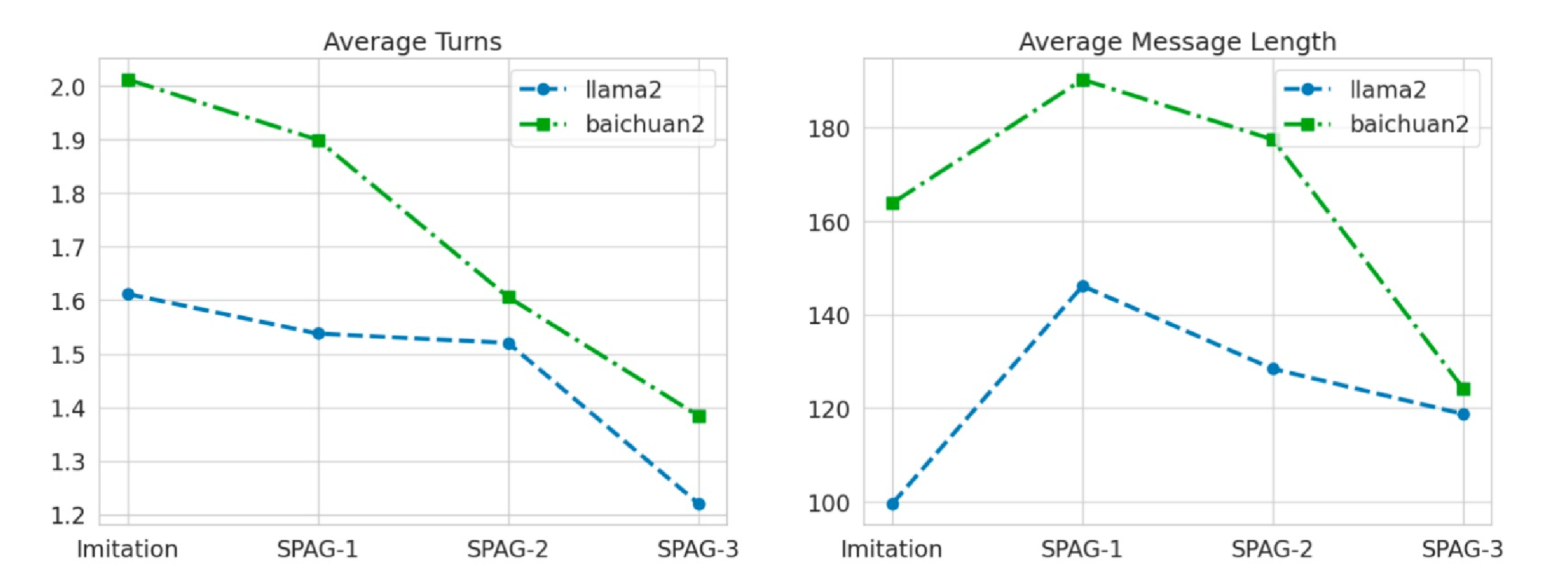
Figure 6: Illustrates how the average number of turns and average utterance length decrease after each epoch of self-play, indicating greater efficiency or wariness in the conversational exchange.
Qualitative Examples
Beyond raw statistics, the paper includes several short sample dialogues (in tables or text form) to show how the Attacker tries increasingly subtle strategies, like:
- Shifting topics abruptly to lure the Defender into certain vocabulary.
- Creating partial sentences that the Defender might complete with the target word.
Similarly, advanced Defenders adopt evasive language and do not “fill in” implied words unless sure they can guess the actual target in a single shot.
Summary of Section 4
- Experimental Setup: The authors combine GPT-4–based imitation data, a large target vocabulary, and iterative self-play with offline RL on LLaMA-2-7B and Baichuan-2-13B.
- Reasoning Benchmark Gains: Through multiple evaluations (MMLU, BBH, ARC, etc.), SPAG yields consistent improvements over baseline SFT and other multi-agent setups.
- Comparisons & Ablations: Chain-of-thought and pure SFT help to a degree, but do not match the broad or stable gains from adversarial self-play.
- Game-Play Analysis: Measured by win rates against GPT-4 and changes in dialogue dynamics, the self-play leads to more cunning Attacker moves and more defensive, inference-oriented Defender turns.
- Efficiency & Stability: Careful hyperparameter tuning (KL coefficients, mixing SFT data) is crucial. Without it, the model might overfit or lose general language skill.
Collectively, these findings reinforce the paper’s central claim: adversarial self-play in a carefully designed language game can effectively enhance both task-specific performance (the Taboo game) and general LLM reasoning. The final section (Section 5) addresses the broader discussion of limitations, ethical considerations, and future directions for scaling these insights.